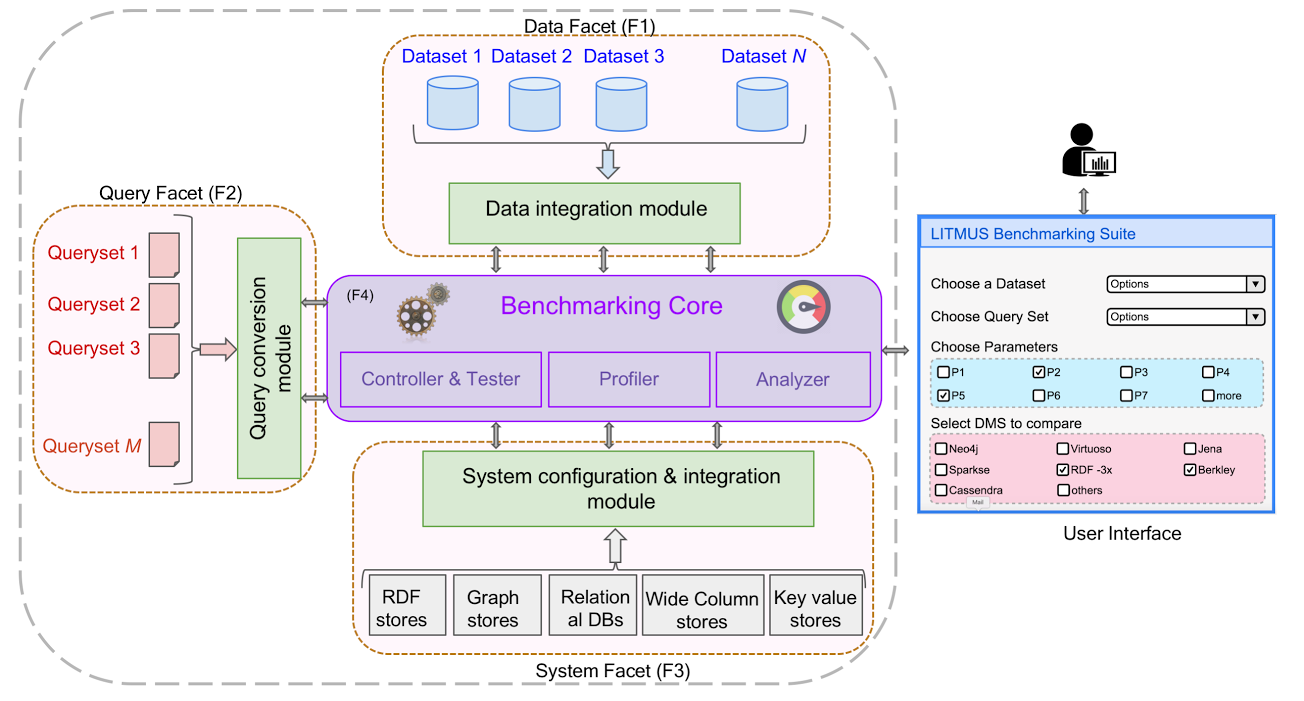
LITMUS
LITMUS Benchmark Suite, is an open extensible framework for benchmarking a plethora of cross-domain DMSs.
Apart from automating the tedious process of benchmarking, it also offers:
- An efficient way for replicating existing benchmarks (e.g., BSBM, WAT-DIV).
- A wide set of performance evaluation measures/indicators tailored specifically for needs and,
- Present a custom visualization via custom charts, graphs and tabular data of the benchmark results for a faster insight.